- Monday Momentum
- Posts
- The Post-Training Revolution
The Post-Training Revolution
Why the race for compute is shifting from pre-training to post-training and what this means for your production architecture decisions
Justin Wright
January 26, 2026 • Est. Reading Time: 5 minutes
Happy Monday!
The AI headlines still read like an arms race. OpenAI has $1.4 trillion in compute commitments. Anthropic just locked in a multi-billion dollar deal for up to one million Google TPUs. The numbers are absurd.
But if you look at where that compute is actually going, something changed in the last six months. The era of "just make it bigger" is ending, not because the scaling laws broke, but because the economics and physics of pre-training hit a wall.
Pre-training data is running out. Token horizons are unmanageably long. And the most capable teams in AI are quietly shifting their compute budgets from building bigger foundation models to something else entirely: post-training optimization.
The AI industry is running out of high-quality pre-training data and hitting limits on foundation model scaling. OpenAI, Anthropic, and Google are shifting compute resources from building bigger base models to post-training techniques like RLHF, DPO, and inference-time scaling. This changes what matters for production systems: fine-tuning beats foundation model selection, post-training data becomes a proprietary moat, and inference costs become the new bottleneck.
The Data Wall Nobody Talks About
The scaling laws that powered GPT-3, GPT-4, and Claude worked because you could feed models more compute and more data. The Chinchilla formula told you exactly how much data you needed for a given model size. Then you trained and hoped for emergent capabilities.
This playbook hit a wall in 2025. The industry ran out of high-quality text data. Web scraping reached diminishing returns. Synthetic data helped but introduced new problems. Token requirements for training became so long that even trillion-dollar companies started worrying about the physics of it.
IBM predicted 2026 would be the year the industry bifurcates between frontier models and efficient models. They were half right. The bifurcation is actually happening inside every major lab, and it's not about model size. It's about where you spend your compute.
The focus in 2026 isn't on building the biggest model. It's on refining and specializing models after pre-training.
"The next phase won't be won by the biggest pre-training runs alone, but by who can deliver the most capability per dollar of compute."
Where the Compute Actually Went
Anthropic expanded its Google Cloud partnership to access up to one million TPUs, a deal worth tens of billions of dollars. OpenAI has $1.4 trillion in compute commitments over eight years to Oracle, AMD, and Broadcom.
If you read the headlines, this looks like more of the same: bigger models, more parameters, AGI through brute force.
If you read the technical roadmaps, it's different. Companies are dedicating increasing portions of their compute resources to post-training techniques. RLHF (reinforcement learning from human feedback), DPO (direct preference optimization), supervised fine-tuning, and inference-time scaling.
The math here matters. DPO delivers RLHF-equivalent performance with 40% less compute. Expert data curation provides 25-35% accuracy improvement. RLHF doubled GPT-4's accuracy on adversarial questions, not bigger pre-training.
Anthropic's Daniela Amodei put it directly: the next phase is about capability per dollar of compute. That's a post-training optimization problem, not a pre-training scale problem.
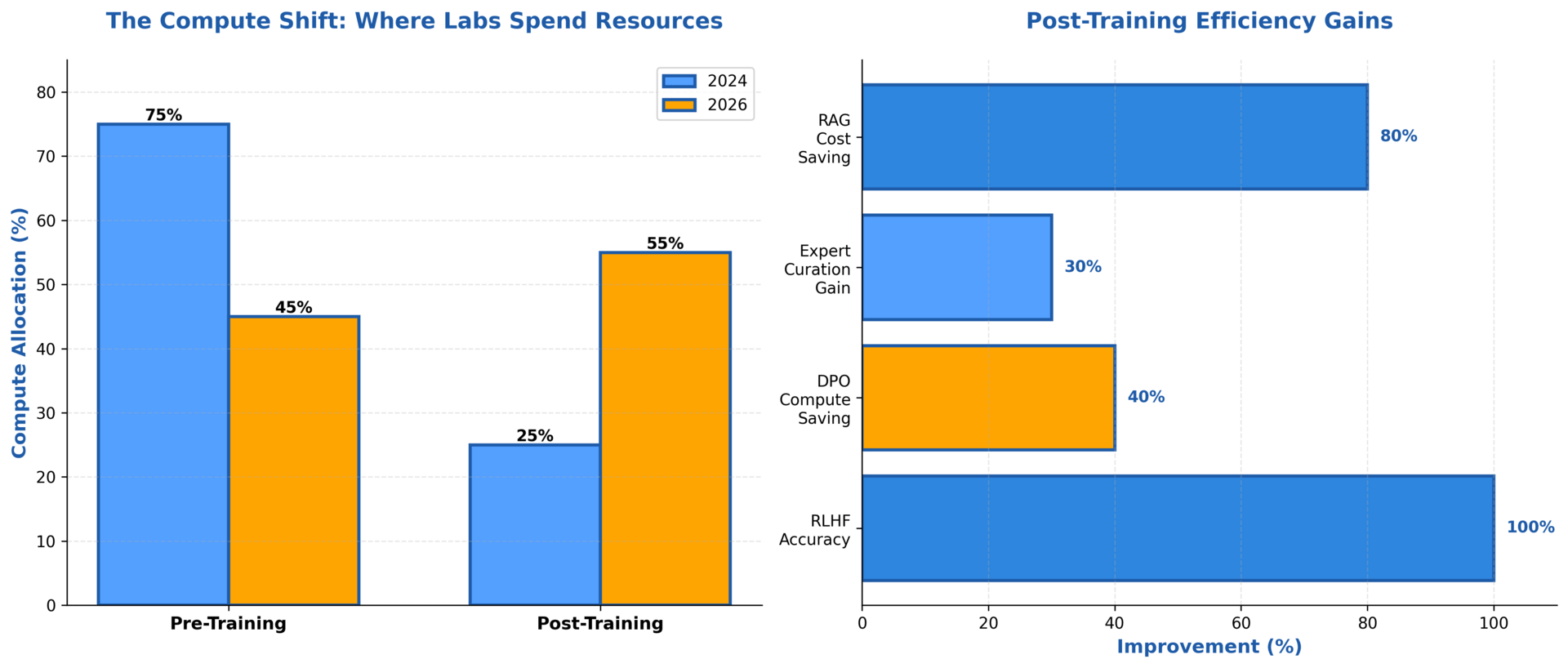
Compute allocation is shifting from pre-training (75%→45%) to post-training (25%→55%), and the efficiency gains justify it: 40-100% improvements across techniques.
The Techniques Reshaping Production AI
The post-training toolkit expanded fast in 2025 and is accelerating in 2026. If you're building production systems, these techniques matter more than foundation model selection.
RLHF remains the workhorse. Models refined with RLHF surpass their base versions on factual accuracy, safety, and task-specific performance. OpenAI credited RLHF for GPT-4's improvements. Anthropic uses it extensively for Claude. But RLHF is expensive because it requires human preference labels at scale.
DPO emerged as the efficiency play. Direct preference optimization delivers comparable results to RLHF with 40% compute reduction by eliminating the reward model training step. For production teams with budget constraints, DPO is the pragmatic choice.
RLVR (reinforcement learning with verifiable rewards) is the new frontier. The "V" stands for verifiable, meaning deterministic correctness labels for math and code domains. You don't need expensive human feedback when you can verify correctness programmatically. This unlocks post-training at scale for technical domains.
Inference-time scaling is the wild card. Instead of making models bigger during training, you make them think longer during inference. OpenAI's o1 model proved this works for reasoning tasks. The model spends more compute at query time, improving output quality in exchange for higher latency and cost per request. This represents a fundamental trade-off: you're not paying for bigger parameters, you're paying for longer thinking time. Expect more focus on inference-time optimization in 2026 as labs explore this third dimension of scaling beyond data and parameters.
For builders, this means your competitive advantage shifted. Foundation model access is commoditized. Every major provider offers similar capabilities at similar prices. Post-training expertise and domain-specific data are the new moats. The teams winning aren't the ones with access to the best APIs, they're the ones with the best feedback loops, the cleanest domain data, and the deepest understanding of which post-training technique to use when.
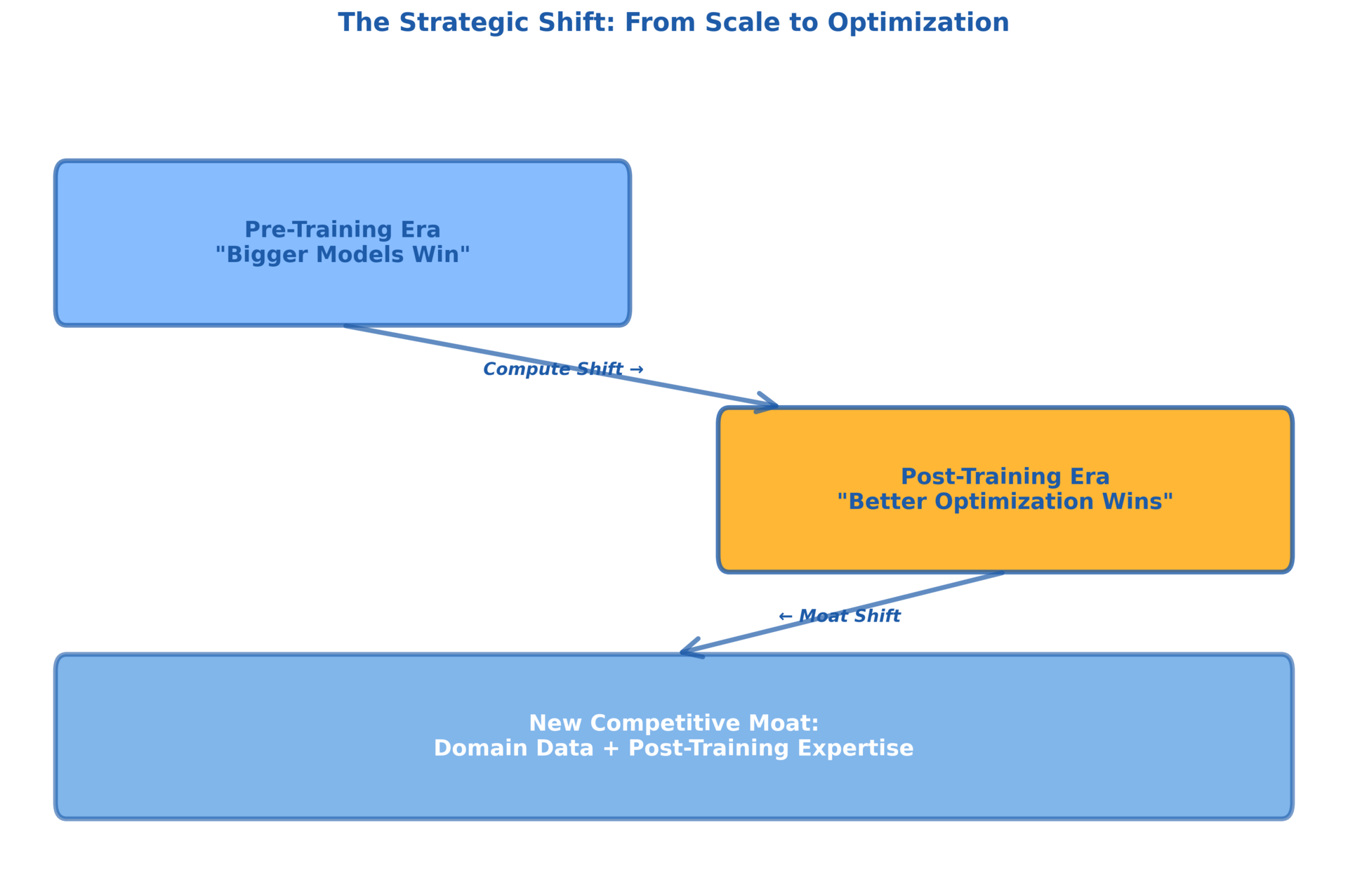
The strategic shift reshaping AI: from 'bigger models win' to 'better optimization wins,' with domain data becoming the new competitive moat.
What This Means for Your Architecture
If post-training matters more than pre-training, your production decisions change.
Fine-tuning beats foundation model selection. A well-tuned 7B model on your domain data will outperform a frontier 405B model for your specific use case. The capability gap closed because post-training techniques are more effective than adding parameters.
Your training data becomes your moat. Proprietary post-training data compounds. Every customer interaction, every feedback loop, every domain-specific example makes your model better for your use case. Foundation model providers can't replicate this.
Inference costs become the bottleneck. Inference-time scaling (letting models "think" longer) improves output quality but increases latency and cost per query. You'll optimize for this trade-off more than training costs.
RAG + fine-tuning beats pure scaling. Retrieval-augmented generation combined with fine-tuned models delivers 80% cost savings versus retraining foundation models from scratch. This architecture pattern becomes standard in 2026.
Post-training expertise matters more than compute access. Knowing how to implement RLHF, DPO, or RLVR effectively matters more than having access to the biggest base model. The technical bar for competitive AI products shifted from "call the API" to "optimize post-training pipelines."
The Bottom Line
The AI industry isn't slowing down. It's changing where it competes.
Pre-training will continue. Frontier models will still push capabilities. But the differentiation, the competitive moats, and the production wins are happening in post-training optimization.
For practitioners, this is good news. You don't need trillion-dollar compute budgets to build competitive AI products. You need domain expertise, quality training data, and post-training technical skills.
The companies that win in 2026 won't be the ones with the biggest models. They'll be the ones with the best post-training pipelines, the most effective fine-tuning processes, and the clearest understanding of the capability-per-dollar equation.
The shift is already happening in roadmaps and budget allocations. The question is whether your architecture is ready for it.
In motion,
Justin Wright
If post-training data becomes the primary competitive moat and foundation models become commoditized infrastructure, what happens to the $1.4 trillion in compute commitments and the companies whose entire value proposition is "we have the biggest model"?

The State Of LLMs 2025: Progress, Progress, and Predictions - Sebastian Raschka
6 AI breakthroughs that will define 2026 - InfoWorld
Anthropic's 'do more with less' bet has kept it at the AI frontier - CNBC
Optimizing LLM Training Data in 2026 - Aqusag
Post-training methods for language models - Red Hat Developer
If you haven’t listened to my podcast Mostly Humans: An AI and business podcast for everyone yet, new episodes drop every week!
Episodes can be found below - please like, subscribe, and comment!